Abstract
探索了如何生成一系列思维链——一系列中间推理步骤——显著提高大型语言模型执行复杂推理的能力。the simple method called chain of thought prompting,
在三个大型语言模型上的实验表明,思维链提示提高了一系列算术、常识和符号推理任务的性能
在数学单词问题的GSM8K基准测试达到SOTA,超过基于微调的GPT3
论文图显示了“思维链推理”的过程,我感觉其实就是采用记录中间变量的形式来完成推理
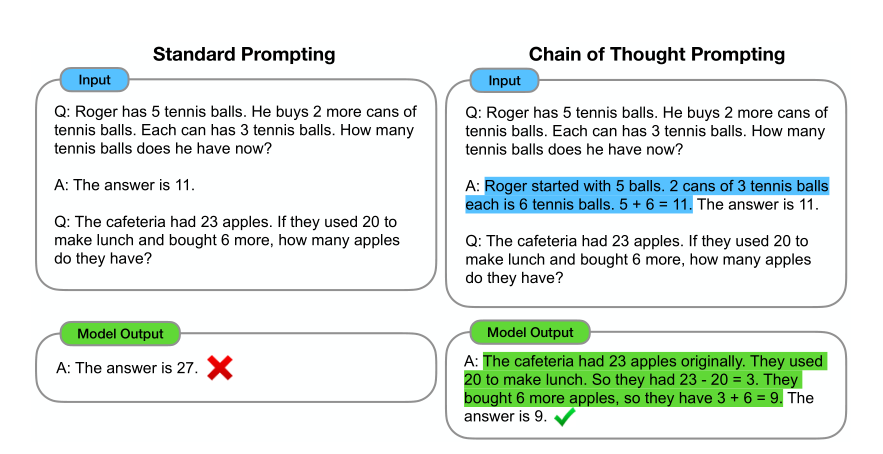
Introduction
- 扩大模型的规模可以带来好处例如:提高性能和样本效率。但是不足在以具有挑战性任务上(算术、常识推理)提高性能
- 作者这些工作主想突出两点:
- 在符号推理中当所需的输入-输出映射涉及多个计算步骤时,生成中间结果可以显著提高准确性
- few-shot learning via prompting has proved successful for a range of simple question-answering tasks
- 作者做了实验评估证明思维链的效果,并且提到只有提示的方法很重要,因为它不需要大的训练数据集
Chain of Thought
- 思维链就是: 问题分解 -> 逐步解答 -> 直到最终答案
- 如何让模型学会思维链?通过prompt,即在示例中提供了少量提示的思维链推理演示,使得大的语言模型能够生成思维链
- 作者列举思维链的特点:
- 提供了一个可解释的窗口,即能了解模型分析推理的过程
- 思维链不仅用于数学、常识和符号推理,还具有通用性(原则上来讲 - _ -。。)
- 让模型引出思维链推理只需要少量的提示性信息
Arithmetic Reasoning
Experimental Setup
Baselines: 标准的prompt, 即直接告诉正确答案
Chain of thought: 手动合成了一组八个带有提示思想链的少数镜头示例。
Language models:
- GPT-3,350M、1.3B、6.7B和175B
- LaMDA,422M、2B、8B、68B和137B
- PaLM,8B、62B和540B
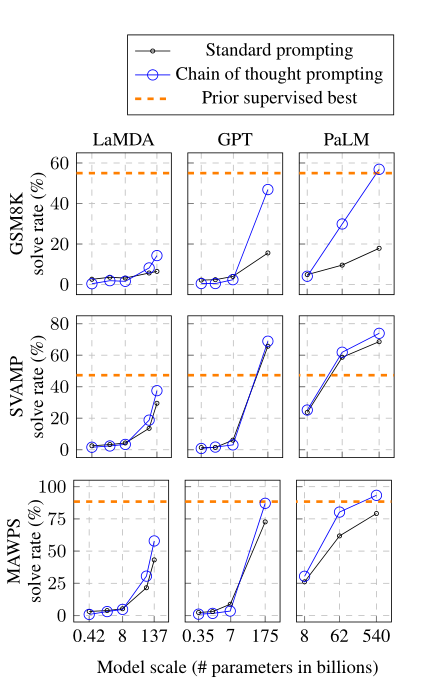
Results:
最好结果表示,思维链激励不会对小型模型的性能产生积极影响,只会在与参数大于100B使用时产生性能增益(bert-base的参数才110M…)
思维链对于更具复杂的问题性能增益更多,对于简单到一步就能得到答案的问题增益较少,甚至是负增益。
通过GPT-3 175B和PaLM 540B进行的思维链提示的性能与现有技术(微调GPT)相比是有利的。
作者检查了LaMDA 137B为GSM8K生成的模型生成的思维链。
- 50个正确答案中,生成的思维链在逻辑上和数学上基本是正确的
- 50个错误答案中,生成的思维链中46%是正确的,导致答案错误的原因是计算器、符号映射错误或缺少一个推理步骤
- Ps:“只要答案是正确的,那么生成的思维链就基本正确” 这件事为后来的STaR论文创新点埋下伏笔
增加参数可以提高思维链推理能力,譬如:PaLM扩展到540B修复了62B模型中的大部分一步缺失和语义理解错误
Ablation Study & Robustness
- Equation only: 在给出答案之前,提示模型只输出一个数学方程
- Variable compute only:将思维链推理过程中所有中间数字变量替换成(…)
- Chain of thought after answer: 思维链提示仅在答案之后给出
- Robustness experiments show that 不同的提示集都比标准基线有很大的优势,因此思维链的成功运用并不取决于特定的语言风格。
Discussion
- 第一个实验表示思维链提示大大提高了算术推理的性能,第二、三个实验强调了思维链推理的语言性质以及如何使其普遍适用
- 标准prompt 原则上只提供了大型语言模型能力的下限,随着模型的扩大,更新的提示方法或许能拉高大型语言模型能力的上限
- 尽管思维链模拟了人类推理者的思维过程,但这并不能回答神经网络是否真的是“推理”,我们将其作为一个开放的问题
- 思维链推理的出现仅限于大模型规模,这使得其在现实世界中的应用成本高昂;未来的工作可以探索如何在较小的模型规模下进行推理。